
Cazena’s cloud data lake team carefully tracks the latest architectural approaches and technologies against our customer’s current requirements. We’ve seen much more interest in real-time streaming data analytics with Kafka + Apache Spark + Kudu. Companies are using streaming data for a wide variety of use cases, from IoT applications to real-time workloads, and relying on Cazena’s Data Lake as a Service as part of a near-real-time data pipeline. Here is what we learned about stream processing with Kafka, Spark and Kudu in a brief tutorial.
This is an example of a streaming data analytics use case we see frequently:
1. Stream data in from a Kafka cluster to a cloud data lake, analyze it, and expose processed data to end users and applications. This requires a cloud data lake with embedded analytic engines, such as Cazena’s Cloudera-powered Data Lake as a Service.
2. Furthermore, once the data is streamed in, merge historical and new data in-stream.
3. Finally, performance is key! The system needs to be able to ingest, transform, and write data quickly, i.e. with sub-second, end-to-end latencies would be nice. Analytical result data should be available for immediate consumption, and end-user queries should run quickly too.
One can come up with a bunch of possible complicated architectures for this use case in Hadoop.
For example, we could use Hbase for fast random reads and writes. Or, we could store data in a Parquet-formatted table on HDFS and use Impala for interactive analytics. Then, those tables will be query-able in Spark and Hive, and we could use a total of four different execution engines on a single cluster, taking advantage of the strengths of each. Plus we would need to make sure to tune them all to run well under load.
If that sounds like an unappealing and time-consuming project, may we could recommend something simpler?
Using Cazena as Part of a Near Real-Time Data Analytics Pipeline
We’ve architected Cazena’s Data Lake as a Service to support near-real-time streaming data analytics use cases for demanding projects. In addition to us spending many hours benchmarking new technologies for our platform — we’ve added automation, workload optimization and built-in DevOps.
Cazena’s End-to-End Data Stream Processing and Analytics Architecture
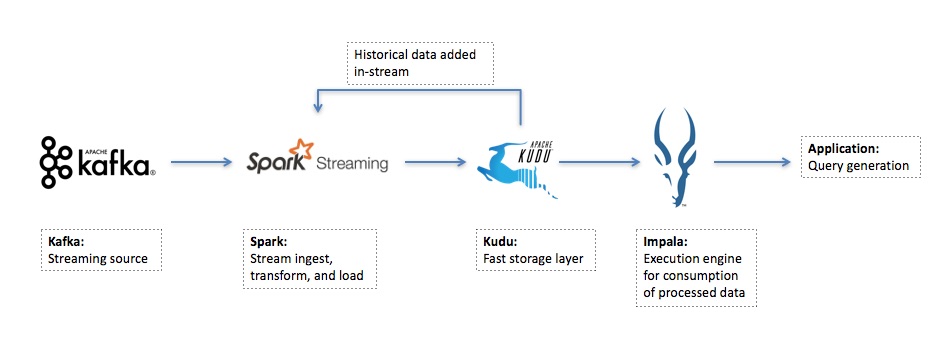
We’ve found that there is a lot to like about a combination of Spark Streaming (ETL) and Kudu (storage layer) tool kit for this workload:
- Kafka streams the data in to Spark.
- Spark handles ingest and transformation of streaming data (from Kafka in this case), while Kudu provides a fast storage layer which buffers data in memory and flushes it to disk.
- We can use Impala to query the resulting Kudu table, allowing us to expose result sets to a BI tool for immediate end user consumption.
We like this approach because the overall architecture of the system becomes vastly simpler:
- There are just two components to manage.
- All code can be written in a single Spark-supported language – we chose Scala.
- The system runs quite fast end-to-end. We’ve had customers see 100x performance improvements compared with more dated streaming technologies, with sub-second Spark Streaming batch sizes, all on a cluster with relatively few cores.
The resulting code base is also succinct and maintainable. Programmers will note that the Spark DataSets and DataFrames APIs are high-level and well designed; Spark Streaming’s micro-batch architecture allows for extensive code re-use with other Spark components; and Spark’s Kudu API is efficient, allowing for high throughput and horizontal scalability. To give an example of this, a parallelized upsert from a Spark DataFrame in to a Kudu table is a one-liner:
kuduContext.upsertRows(sparkDataFrame, kuduTableName)
If you’d like to see a working example, please take a look at our Cazena code book. As an aside, Spark Streaming also provides decent out-of-the-box monitoring tools. Take a look at the standard graphs on Cloudera’s website showing real time ingest rates and backpressure.
Kudu Limitations: Not “One Size Fits All”
At the same time, we’ve also found this is not a one-size-fits-all tool kit. Though extremely powerful and easy to use, Kudu does have some limitations to be aware of. The list of supported variable types in Kudu is short. Kudu is opinionated when it comes to data quality and any bad data will probably be rejected, meaning it needs to be written elsewhere and handled separately. Also, Kudu is strict about being a column-based data store. That means it needs structured and typed data (no JSON, no Avro, no unstructured text files), and currently supports no more than 300 columns per table.
Having said that, Spark and Kudu are actively developed and widely used projects. Getting up and running is quite fast, particularly on a pre-configured Cazena platform. On a Cazena Data Lake as a Service with the Cazena code book, a logged-in user can test reads, inserts, and upserts from Spark to Kudu in less than 30 seconds. And the overall performance, maintainability, and scalability of this tool kit make it a strong choice for a very valuable use case.
Drop us a note if you have an interesting streaming use-case with similar architectural requirements.