
It can be hard to present the first session of the day at a tech conference, especially on day two, after the previous night’s parties. Frankly, I worried no one would come. On Twitter I threatened to bring my ukulele and sing parody songs about the cloud – “Rockin’ The PaaS-bah” or “IaaS a Rock” (IaaS an island?). But when a good crowd of attendees streamed in just before the start time, sans beers or concert t-shirts, I decided to stick with the planned presentation and spare them my songwriting skills.
Using the cloud for data processing is a new concept for many. My goal was to provide a basic primer about Big Data in the Cloud. I approached the subject as I did back in my tech journalism days: lots of research, reading and talking – synthesized down to 30 minutes. I encouraged interactive discussion, and I got it! Here are the conversation highlights, with a few song lyrics to keep you inspired.
“It’s cloud illusions I recall. I really don’t know clouds at all.”
(Both Sides Now, Joni Mitchell, 1967)
In researching the session, I found over 20 different category labels for cloud data solutions, with significant overlaps: big data as a service, data warehouse as a service, Hadoop as a service, database platform as a service, data management as a service, cloud data services…the list goes on (and on.) Session attendees even brought up some new ones I hadn’t heard yet! It’s confusing right now. We all agreed that functionality matters more than category labels, but myriad different terms confuse buyers. The industry will start to rationalize this, but until then, assume no consistency in labels and focus on your requirements.
“Spread your wings and you’ll take to the sky…”
(Summertime, George Gershwin, 1934)
Most enterprises have made significant investments in on-premises infrastructure for data management. Leveraging the cloud effectively often requires a flexible, hybrid data architecture that spans existing on-premises and new cloud infrastructure. However, there’s no one-size-fits-all strategy for which processes live in the cloud vs. on-premises. It depends on existing infrastructure and the types of data and analytics involved. Increasingly, the trend is to move analytic processing to the data (especially for truly big data), but that’s not always easy, especially when combining multiple datasets. Session participants discussed many different ideas and considerations for the hybrid model, ranging from network latency to global compliance. Bottom line, there are many ways to do hybrid.
“There must be 50 ways…”
(50 Ways to Leave Your Lover, Paul Simon, 1975)
There are many ways (more than 50, even!) to use the cloud for data processing. Many companies plan to use the cloud for big data. A recent Big Data Analytics survey by Eckerson Group/SearchBusinessAnalytics found that over half of those with big data programs plan to use the cloud. Our group reported a similar trend. The elasticity of the cloud offers obvious benefits for high-volume, big data analytics. But exactly how companies use the cloud varies. There’s a continuum, ranging from digital natives with all data in the cloud to enterprises experimenting with a few workloads in the cloud.
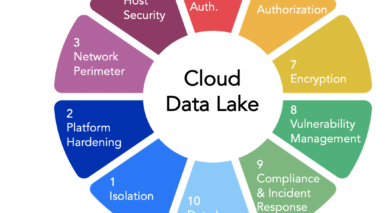
One use case in particular generated the most discussion: using the cloud as an incoming filter for data already outside the firewall. In this scenario, companies use the cloud to collect raw data from sensors, mobile apps or third parties. They pre-process it in a cloud data lake before moving a subset to on-premises systems. Attendees agreed this might be the best place to start for more cautious enterprises. (Related, Cazena recently shared some helpful expertise on building cloud data lakes.)
Even after the session, we continued to share ideas, questions and other considerations for the cloud and big data. Not bad for the first session of the day!
Source: The blog title references the lyric “Gone are the dark clouds that had me blind…” from the song I Can See Clearly Now, Johnny Nash, 1972.